-
微信
 微信扫一扫
微信扫一扫 - 搜索
西安学习大数据想去好的学校学习,可以到西安兄弟连大数据培训学校,学校开设大数据培训班每个月定期开班,想学习大数据的朋友均可报名,学校严格、科学、负责的教务管理体系,班主任全程监管,关注每个学员的学习状态,保障教学质量。设有专业的职场实践课和就业指导课,企业进校招聘,为学员提供多渠道的就业服务。

大数据,英文是big data,是数据集合和信息资产。其战略意义不在于它的庞大,而是在于对这些数据进行专业化处理。换而言之,如果把大数据比作一种产业,那么这种产业实现盈利的关键,在于提高对数据的加工能力,大数据开发就是通过加工实现数据的增值。从技术上看,大数据与云计算密不可分。因为大数据无法用单台的计算机进行处理,必须采用分布式架构,依托云计算的分布式处理、分布式数据库和云存储、虚拟化技术,对海量数据进行分布式数据挖掘。
—学大数据,课程好才是好机构—
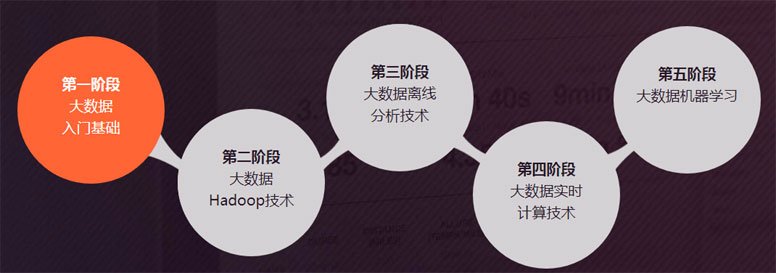
以企业需求为导向,历经多家企业验证,上课形式有线下实训、线上IT云课堂、战狼特训营等。分阶段教学,循序渐进。
—学大数据,老师好才是好机构—
拥有来自北大、清华和BAT等知名校企的专兼职教师数百名。

—学大数据,就业好才是好机构—
西安兄弟连大数据培训机构地址在西安市高新区高新路,电话和微信见下图,关于大数据培训的课程、学时、学费、就业等各方面的问题,都可以向我们咨询,我们一定详细解答。

hadoop的shuffle过程
一、Map端的shuffle
Map端会处理输入数据并产生中间结果,这个中间结果会写到本地磁盘,而不是HDFS。每个Map的输出会先写到内存缓冲区中,当写入的数据达到设定的阈值时,系统将会启动一个线程将缓冲区的数据写到磁盘,这个过程叫做spill。
在spill写入之前,会先进行二次排序,首先根据数据所属的partition进行排序,然后每个partition中的数据再按key来排序。partition的目是将记录划分到不同的Reducer上去,以期望能够达到负载均衡,以后的Reducer就会根据partition来读取自己对应的数据。接着运行combiner(如果设置了的话),combiner的本质也是一个Reducer,其目的是对将要写入到磁盘上的文件先进行一次处理,这样,写入到磁盘的数据量就会减少。最后将数据写到本地磁盘产生spill文件(spill文件保存在{mapred.local.dir}指定的目录中,Map任务结束后就会被删除)。
每个Map任务可能产生多个spill文件,在每个Map任务完成前,会通过多路归并算法将这些spill文件归并成一个文件。至此,Map的shuffle过程就结束了。





